Problem:
Przy uruchamianiu job'a w Databricks dostajemy błąd, że nie można połączyć się z Azure Devops repository. Błąd występuje losowo. Czasami są tygodnie, że nie występuje. Wystarczy uruchomić ponownie job, żeby wszystko wróciło do normy i ładowanie było kontynuowane. Niestety wymagana jest interwencja człowieka a niestety czasami człowieka nie ma w okolicy. Istnieje potrzeba, żeby w inny sposób skonfigurować uruchamianie jobów.
Rozwiązanie:
A właściwie dwa, które można zastosować. Pull albo push. Czyli albo wysyłamy z Azure DevOps kod do Azure Databricks workspace albo z Databricksów przy użyciu REST API ciągniemy kod z repozytorium. Oba rozwiązania mają swoje zalety i wady i przyjrzymy im się szczegółowo.
PUSH z Azure Devops do Databricks
Skorzystamy z Azure Devops Release. Tam jest zadanie (task), który wystarczy skonfigurować i dane z Azure Devops będą lądowały w przestrzeni roboczej Databricks (workspace).
Przy wyborze taska uwaga, bo są dwa które się tak samo nazywają ale mają inne parametry wejściowe. Wybierz ten dostarczany przez zewnętrznego dostawcę niż Microsoft. Ten task da Ci możliwość połączenie się przy użyciu service principala.

Następnie konfiguracja przebiega prosto wybierasz z którego repozytorium i z którego brancha będą pobierane dane i gdzie będą zapisywane po stronie Databricks. Tutaj mała uwaga: service principal musi mieć uprawnienia (manage) do lokalizacji którą wskazujesz. Gdy nie ma uprawnień wtedy dostaniesz błąd: "Permission denied".

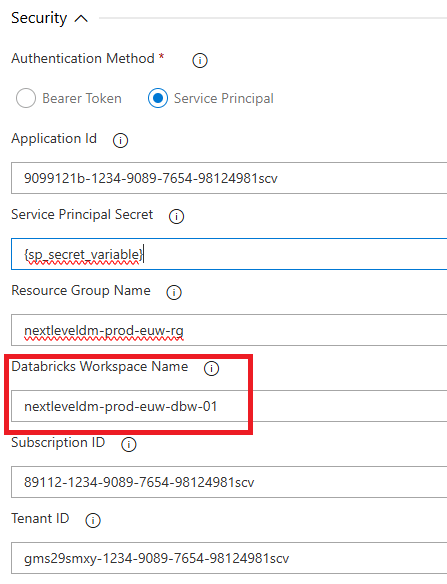
Następnie jest ciekawa cześć dotycząca zakładki security. Większość danych masz, tylko ciekawe, że Databricks workspace name to jest nazwa usługi Databricks w Azure Portalu. To nie jest nazwa hosta, to nie jest workspace id. To jest, powtórzę jeszcze raz, nazwa usługi Databricks w Azure Portalu.
Takiego Releasa można ustawić, żeby był wyzwalany za każdym razem, gdy:
- Zrobiony zostanie pull request
- Zrobiony zostanie push do repozytorium.
Pozwala to utrzymać synchronizację między środowiskiem Azure Devops a Databricks.
PULL z Azure Devops do Databricks
Integracja Azure DevOps z Databricks. Inny przypadek to pobranie danych z Azure Devops z poziomu Databricks. Posłużymy się do tego komendami REST API, które pomagają współpracować z repo.
Do wylistowania, jakie repozytoria teraz mamy skonfigurowane w devops użyjemy tej funkcji:
def get_repos():
return requests.get(f"{DBX_HOST}/api/2.0/repos", auth=BearerAuth())Natomiast potem, żeby aktualizować konkretne repozytorium użyjemy tej komendy:
def update_repo(repo_id: str, branch: str):
data = {"branch": branch}
return requests.patch(f"{DBX_HOST}/api/2.0/repos/{repo_id}", auth=BearerAuth(), json=data)Zaleta tej opcji jest taka, że z poziomu Databricks widzimy z jakiego repo zostały pobrane dane. Czy są jakieś zmiany do zaciągnięcia, czy ktoś coś modyfikował w kodzie Databricks na środowisku.. To jest ciekawa opcja.
Taki job wypadałoby wyzwalać przed startem loadu: aktualizować dane z repo za każdym razem przed startem loadu.
Integracja Azure DevOps z Databricks - Podsumowanie
To jak wolisz robić push czy pull? Co będzie sprawiało mniej problemów?
Na pewno push. Jest to rozwiązanie low code. Za każdym razem, gdy zajdą zmiany w repo, zostaną one odzwierciedlone w Databricks. Z tą małą uwagą, że nie wiesz z jakiego commita i z jakiego brancha dane znajdują się w repo.
Pull wydaje się trochę nadmiarowy, nawet gdy nie będzie żadnych zmian w repo, będziemy wymuszać aktualizację. Ale za to będziesz wiedział, z jakiego brancha i commita masz zaciągnięty kod i co za tym idzie, jaki kod uruchamiasz.
Każde z podejść ma swoje zalety i wady.
Ja skłaniałbym się bardziej ku pierwszemu podejściu. Dlaczego? Bo można to zrobić w 100% przy użyciu service principala i secretów. Nie dodając dodatkowych uprawnień do repo i nie generując dodatkowych tokenów.
Które rozwiązanie jest dla Ciebie ciekawszą alternatywą?